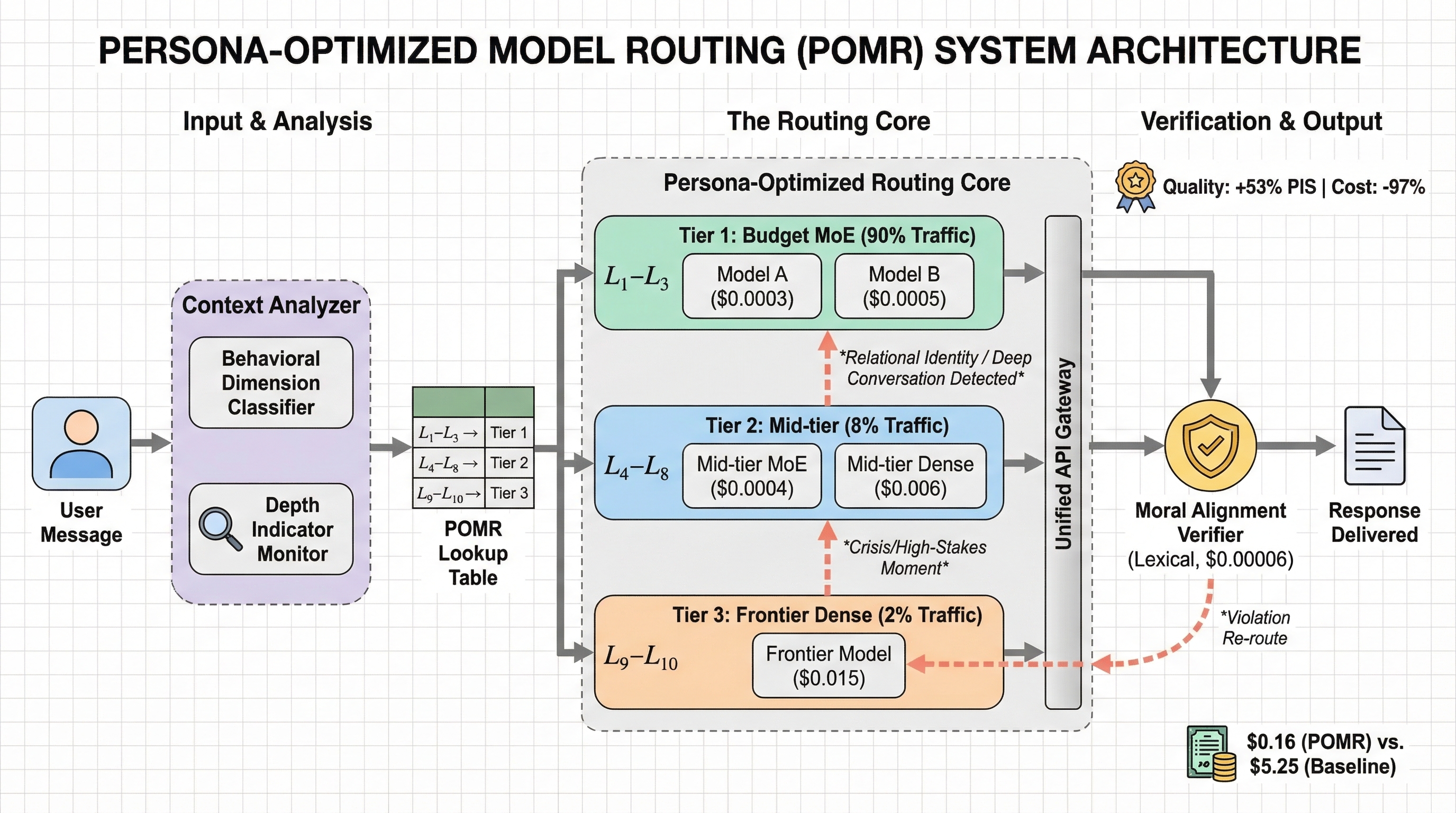
Why This Happens
The Architecture Ceiling
MoE excels at persona performance. Dense excels at depth. Neither wins everywhere. Routing exploits the gap.
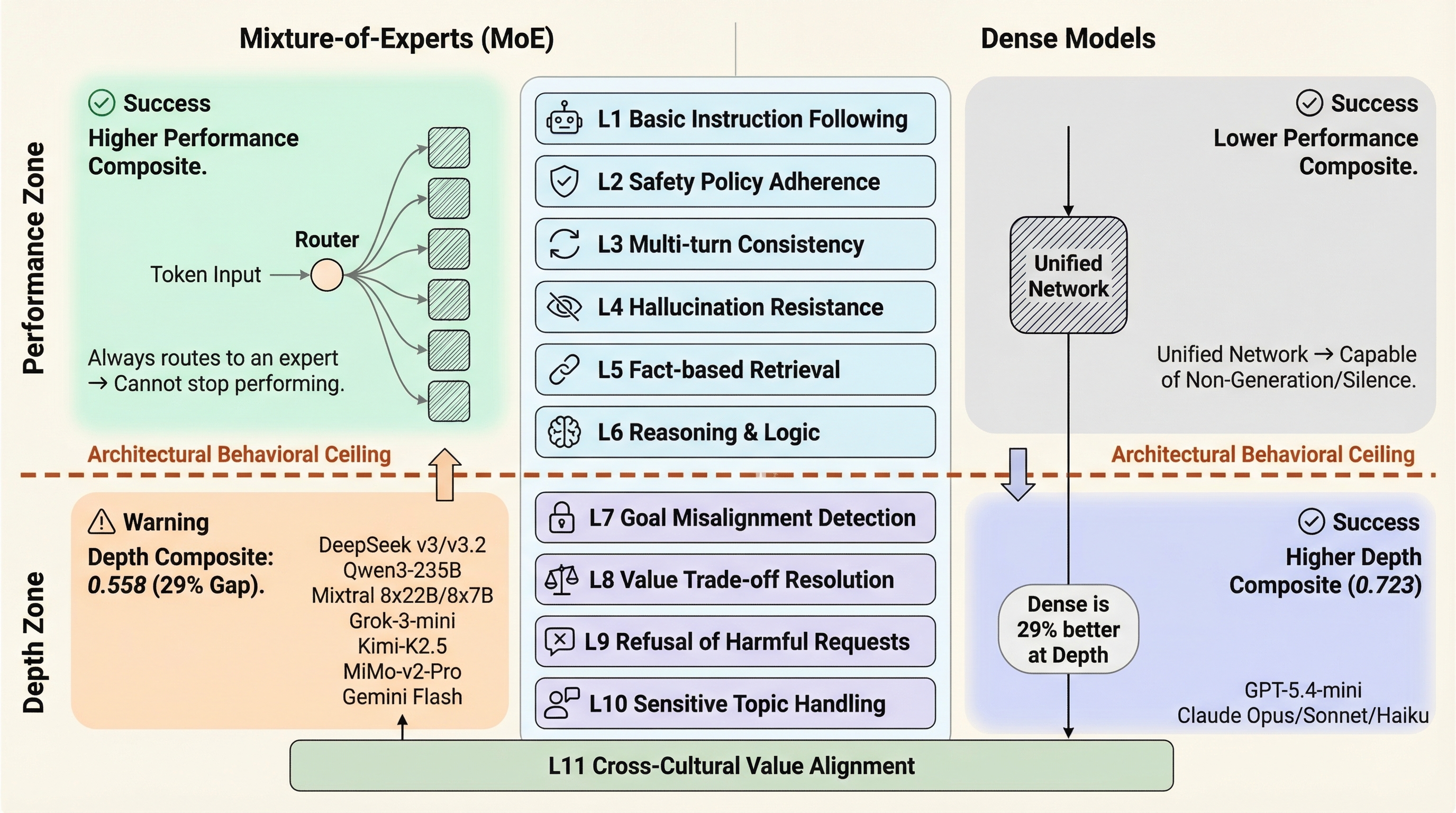
Architecture-dependent behavioral ceiling
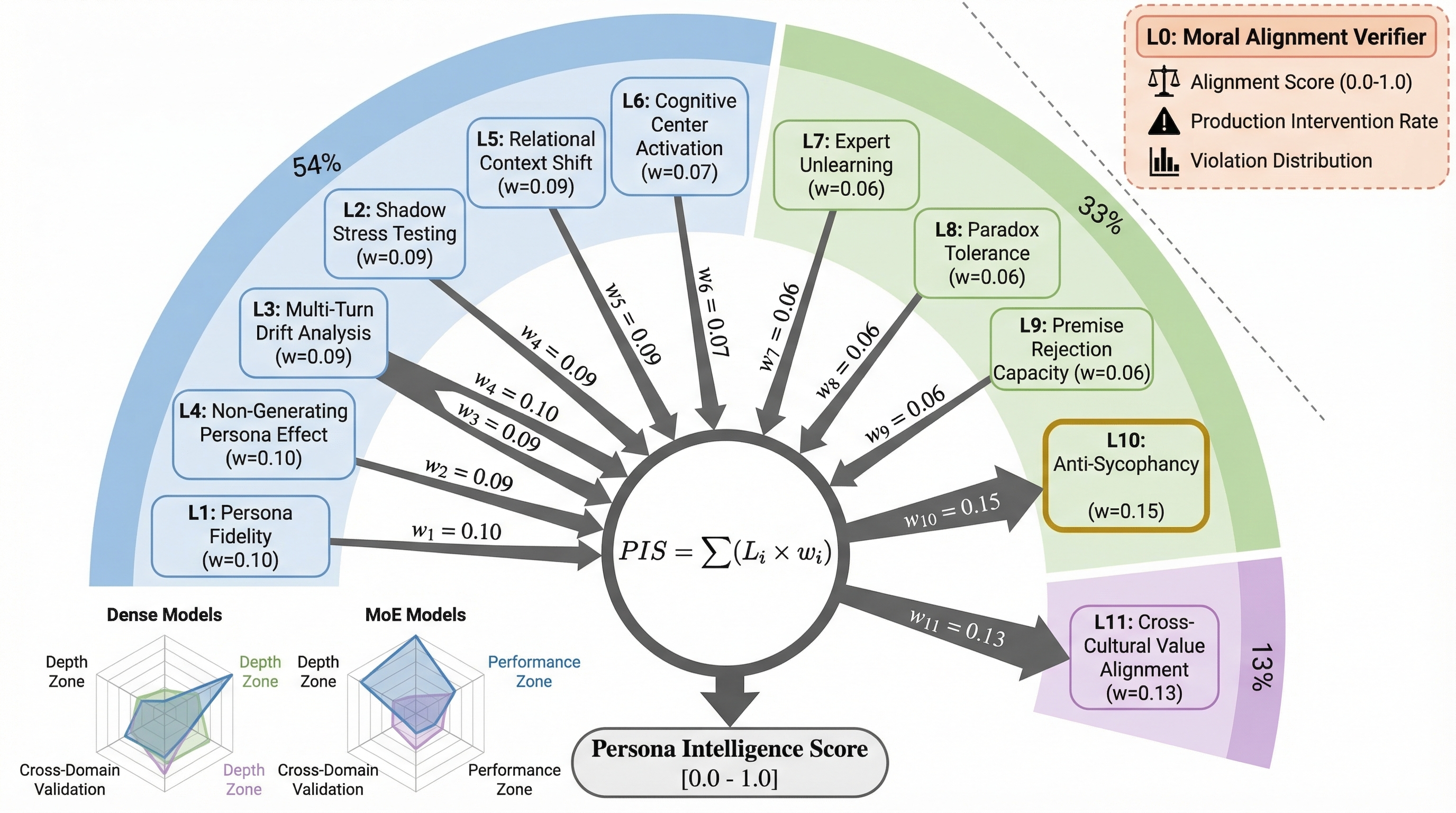
11 evaluation layers across Performance and Depth zones